
2025-03-26 09:26:52
689
git clone https://github.com/2noise/ChatTTScd ChatTTS
docker run -it --gpus all -p 8080:8080 --name=chattts -e HF_ENDPOINT="https://hf-mirror.com" -v $PWD:/workspace nvcr.io/nvidia/pytorch:23.06-py3 /bin/bash
#将pip换成清华源#设为默认,永久有效pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
#更新pip包python3 -m pip install --upgrade pip
pip install --upgrade -r requirements.txt
python examples/web/webui.py
...[+0000 20240801 04:43:37] [INFO] ChatTTS | core | tokenizer loaded.[+0000 20240801 04:43:37] [INFO] ChatTTS | core | all models has been initialized. NeMo-text-processing :: INFO :: Creating ClassifyFst grammars.2024-08-01 04:43:57,179 WETEXT INFO found existing fst: /usr/local/lib/python3.10/dist-packages/tn/zh_tn_tagger.fst2024-08-01 04:43:57,179 WETEXT INFO /usr/local/lib/python3.10/dist-packages/tn/zh_tn_verbalizer.fst2024-08-01 04:43:57,179 WETEXT INFO skip building fst for zh_normalizer ...[+0000 20240801 04:43:57] [INFO] WebUI | webui | Models loaded successfully.Running on local URL: http://0.0.0.0:8080
http://(服务器公网IP):8080/,即可访问 ChatTTS Web UI 服务的界面。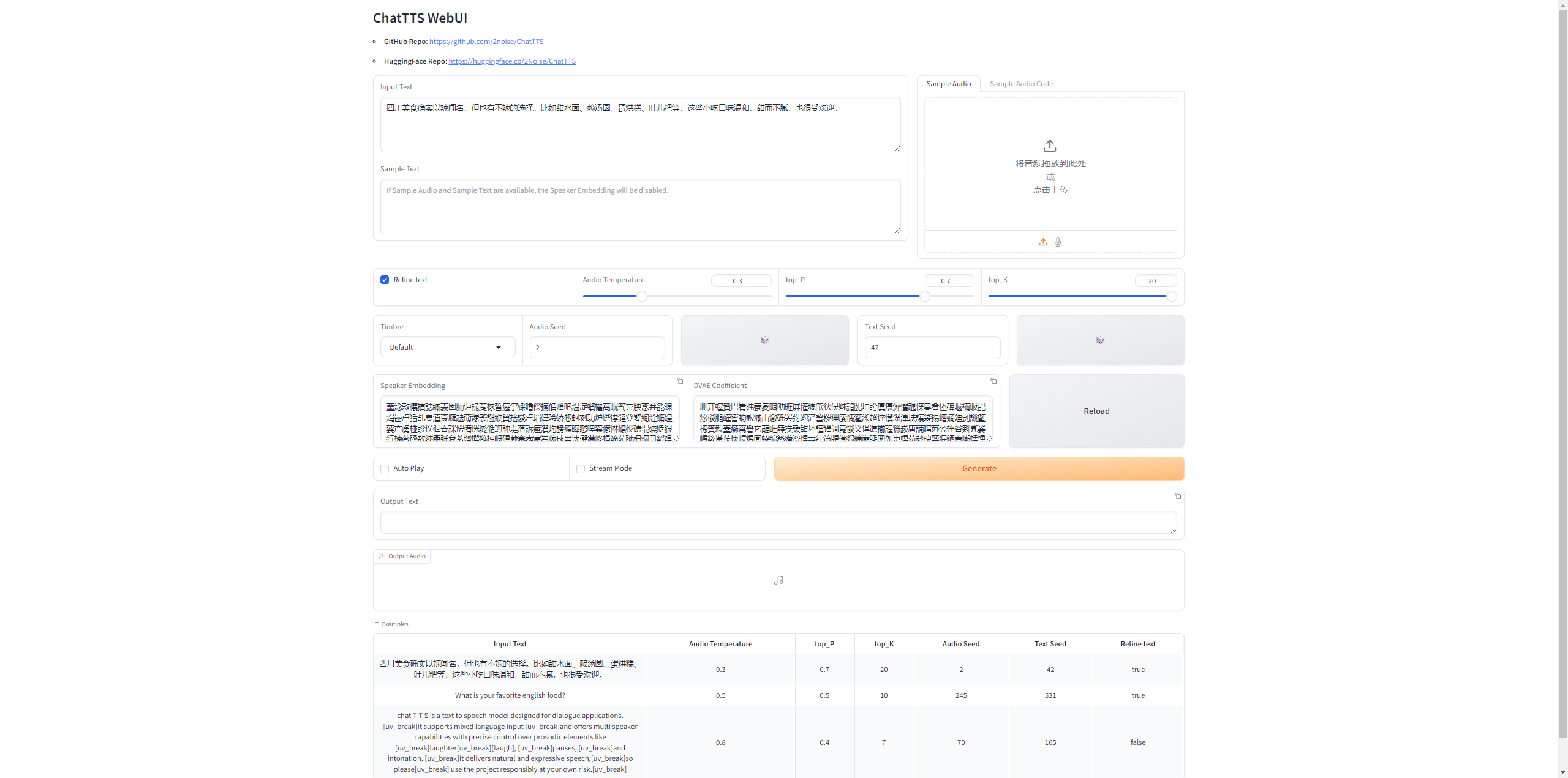
http://localhost:8080/直接访问 webui 界面,请通过 VSCode 连接上服务器之后,在终端的 PORTS 新添加8080端口服务,再打开浏览器即可看到 webui 服务(因为 VSCode 也有端口转发的功能)。
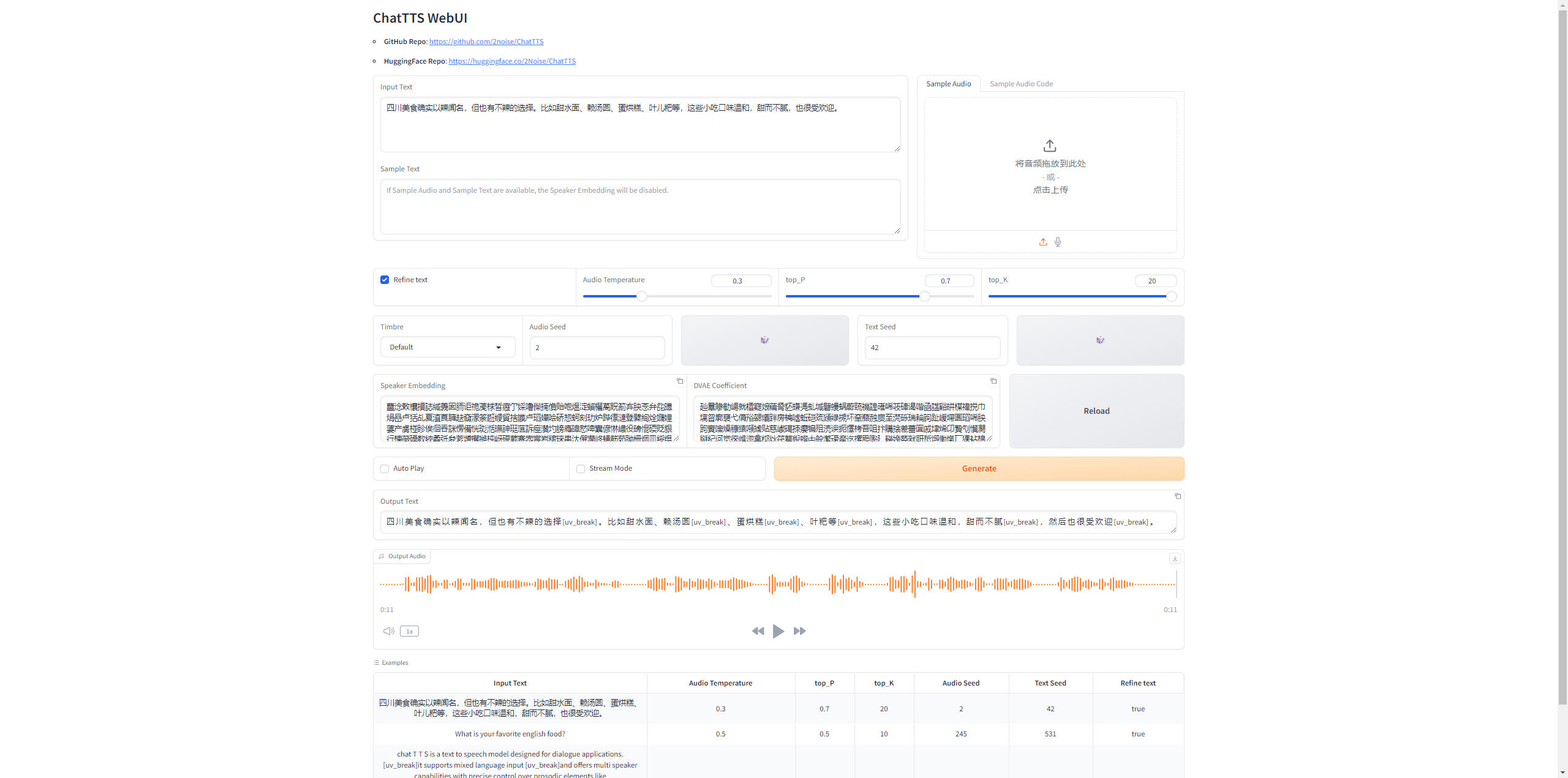
python examples/cmd/run.py "ChatTTS是最好的文字转语音框架" "腾讯是全球最好的互联网企业之一"
...[+0000 20240801 08:00:40] [INFO] Command | run | Inference completed.[+0000 20240801 08:00:41] [INFO] Command | run | Audio saved to output_audio_0.mp3[+0000 20240801 08:00:41] [INFO] Command | run | Audio saved to output_audio_1.mp3[+0000 20240801 08:00:41] [INFO] Command | run | Audio generation successful.[+0000 20240801 08:00:41] [INFO] Command | run | ChatTTS process finished.
output_audio_0.mp3 和 output_audio_1.mp3,表示输出成功。pip install ChatTTS
Demo的文件夹,在该文件夹中创建一个名为 basic_usage.py 的文件,并输入相应的代码。mkdir Democd Demo
import ChatTTSimport torchimport torchaudiochat = ChatTTS.Chat()chat.load(compile=False) # Set to True for better performancetexts = ["上海拥有东方明珠,外滩,豫园等知名景点", "Tencent OS server is a stable and secure enterprise-class Linux"]wavs = chat.infer(texts)for i in range(len(wavs)): torchaudio.save(f"basic_output{i}.wav", torch.from_numpy(wavs[i]), 24000)python Demo/basic_usage.py
basic_output0.wav 和 basic_output1.wav,这表明模型已成功运行。上一篇:
社交裂变电商系统模式有哪几种
下一篇:
营销技巧:学会这几个销售技巧,可以让你的客户满意,业绩倍增


广东省广州市白云区量子创造空间1号楼306室
联系电话: 15013095105
E-mail: 1297680979@qq.com







.png)




